Thndr’s all-hands meeting
During one of those weekly “all-hands” meetings at Thndr⚡️, where we get together to share the week’s updates, everyone was celebrating that around 86% of EGX’s (Egyptian Exchange) investor growth in 2022 was registered and signed up through our Thndr app (Android, and iOS). Amidst the general excitement, as usual, the engineering team had their minds elsewhere and were concerned about something entirely different. Ali, our engineering lead, was thinking about a technical problem that had been looming for a while and was considered a priority technical debt item that should be tackled sometime in 2023. Because of the tremendous increase in the app’s usage, he thought that it would be a better idea to prioritize working on it right away. This was the start of a good conversation that I had with Ali and Seif to figure out when and what to start with.

Hey, it’s Redis again!
Redis is a powerful in-memory data structure store that has become increasingly popular among developers for its speed, versatility, and ease of use. With its ability to handle data structures such as strings, hashes, lists, sets, and more, Redis is a great tool for solving complex problems in real-time applications.
At Thndr we rely heavily on Redis. Our use cases vary between caching, distributed rate limiting, Pub/Sub for most of our background jobs, and even as a persistent key-value store, among others. And while at first, it wasn’t an issue, now, with our growing user base, which grew by more than 400% in the last 5 months, we started seeing a substantial increase in our Redis latency.
We’re using AWS ElastiCache as a managed Redis solution. At the beginning of all of this, we had a single Redis server and database provisioned and used by all our microservices. Some of the data that lives in this database is used by multiple services, and some of it is scoped to a single service. This is the famous “common data coupling” anti-pattern, and gradually, we started seeing more and more issues with this setup, increased latency being one of them. First, we hit our instance bandwidth limit, so we went ahead and scaled our instance vertically so that AWS would give us more bandwidth. The problem was that we were wasting a lot of money as our CPU usage was less than 7% and our memory consumption didn’t exceed 22%. Nonetheless, this solution helped us become resilient for a while. We would still have some latency spikes in market hours that could go up to 1s+ (ideally, Redis should have a latency of 1 ms for writes and much less for reads), but we were coping.
We have a problem..
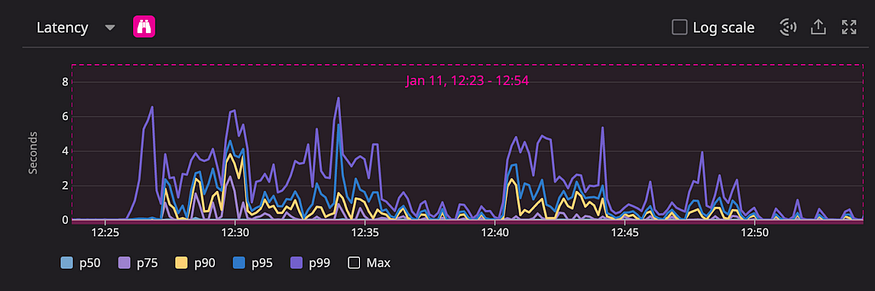
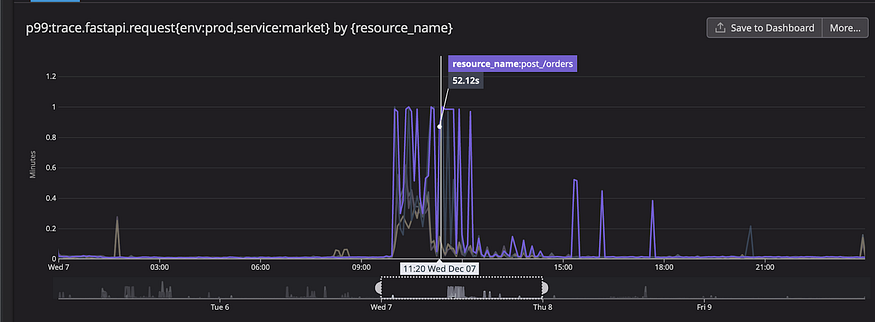
Soon after, this past December, we had our first big incident. It started with a huge spike in latency. Redis requests queue became backed up under the sufficient load, where the requests were being queued much faster than they were being processed. During the incident, Redis’ p99 latency reached the 40s mark. This affected our SLA and the user experience negatively. Our most critical services were affected, and the entire app became very slow. We saw 1+ minute latencies in some of our most important services. This was truly a wake-up call that relying on vertical scaling is not an option anymore and that it was time we addressed the root cause of the problem at hand.
The following graphs demonstrate how this had a significant impact on our latency throughout that incident.
Discovery
As mentioned before, we hit our bandwidth limit in Redis, partially because of our growing user base, in addition to some anti-patterns that we have scattered around the codebase, but more on that later.
Redis is single-threaded by nature, which means no two commands can execute in parallel. This might appear as an issue, but in most cases, network bandwidth and memory bandwidth are the bottlenecks as opposed to the CPU; thus, the performance gain from multi-threading is negligible. Since most threads will end up being blocked on I/Os, it wouldn’t justify the overhead of multi-threading, which includes significant code complexity from resource locking and thread synchronization and CPU overhead from thread creation, destruction, and context switching.
Nevertheless, when you use it to perform multiple key operations periodically on hundreds of thousands of keys, like we were doing at the time, it can take a lot of time to process and block the event loop until it finishes. These expensive O(n) operations, like mset and mget that we used to run, attempt to get more than 25k values at a time. There’s also the usage of the KEYS command, which is a very expensive and blocking operation and should be avoided at all costs in production and replaced instead with SCAN.
Through monitoring tools (we mainly rely on Datadog for this), we found out that unfortunately, our most impacted service is the market service, where all of the trading and most of the magic happens.
Operation “Split and Scale”
First, we started by splitting our huge, monolith Redis database into multiple ones, one for each service. We were able to end up with a Redis database per service for most of our services, except for a few where there’s this common data coupling issue that we mentioned in the intro. Already, by doing this split, we were able to give ourselves a lot of headroom and buy ourselves some time, to focus on the other contributing factors.
Then, we started looking into how to scale the different Redis instances, and naturally, we considered Redis Cluster. Since Redis operates with a single-threaded model, vertical scaling is not really a helpful option, as it is not capable of utilizing multiple cores of the CPU to process commands. So instead, horizontal scaling seems like a more plausible solution. Redis Cluster utilizes horizontal scaling by not only adding several servers and replication the data but also distributing the data set among the nodes in the cluster (what you’re maybe familiar with as sharding) enabling the processing of requests in parallel. What makes Redis Cluster extra special, however, is its sharding algorithm; Redis Cluster does not use consistent hashing, but a different form of sharding where every key is assigned to a hash slot.
Hash slots share the concept of using hashes or composite partitioning but do not rely on the circle-based algorithm upon which consistent hashing is based. One of the drawbacks of consistent hashing is that as the system evolves, operations such as addition/removal of nodes, expiration of keys, the addition of new keys, etc. cause the cluster to end up with imbalanced shards. In a way, this would have created more problems instead of solving them.
The way “Hash Slots” effectively solve this is by partitioning the keyspace across the different nodes in the cluster. Specifically, it is split into 16384 slots where all the keys in the key space are hashed into an integer range 0 ~ 16383, following the formula slot = CRC16(key) mod 16383. To compute what the hash slot of a given key is, we simply take the CRC16 of the key modulo 16384. Doing this makes the evolution of the cluster and its processes (such as adding or removing nodes from the cluster) much easier. If we are adding a new node, we need to move some hash slots from existing nodes to the new one. Same way, if we would like to remove a node, then we can move the hash slot served by that node to the other nodes present in the cluster. In return, this creates a much more balanced cluster, solving the issue with consistent hashing.
One thing to take into consideration though is that AWS Elasticache operates a little bit differently than Redis. So, for example, there is no sentinel mode, so sharding is always obligatory if you’re thinking of adding more nodes to scale horizontally. Also, cluster mode behaves a bit differently than how Redis normally does. Like for example there is no minimum limit of three on the number of nodes that a cluster should have as Redis does. So AWS Elasticache documentation should be consulted first before going through with it as a solution expecting it to behave just like Redis.
Another Discovery
We also looked at the library that we are using now to make calls to our Redis databases. We found that it was deprecated, and didn’t support Redis Cluster. Digging deeper into its source code, we found that it was also not that performative in terms of some multi-key commands. For example, running commands in a pipeline runs the commands in a for loop instead of pipelining the commands. We decided that we should look at other libraries that support the Redis Cluster, which are hopefully much more performative.
Another area for improvement was the fact that we use Redis as a Pub/Sub mainly to schedule celery jobs. In a nutshell, using Pub/Sub with Redis Cluster is generally a bad idea. As the client can send SUBSCRIBE to any node and can also send PUBLISH to any node, the published messages will be replicated to all nodes in the cluster. This makes Redis Cluster as a Pub/Sub solution inefficient.
The Solution
The first thing we did was replace our Celery jobs with Kubernetes jobs instead across all our services to mitigate the load a bit from Redis. An added bonus was that we have much better observability on Kubernetes jobs than we did on Redis jobs anyway.
Then, as mentioned before, our market service is not only the most impacted service, but it’s also one of the most important and most used services in our ecosystem, so we decided to start from there.
We wanted to try implementing Redis Cluster there first and monitor its performance. And since this is a big move, we took it in steps, so we first looked at alternatives to our deprecated Redis library. Our criteria for choosing this library were 3 things;
- Huge support from the Redis community
- Performative operations where for example pipelining is actually pipelining the operations and not just putting them in a for loop under the hood.
- Support of Redis Cluster mode and multi-key commands in cluster mode.
Obstacles along the way
One of the challenges that we faced while picking a library is that, for the aforementioned third point, most libraries didn’t seem to support multi-key commands in cluster mode, which are essential as they are widely used in our codebase (luckily, we don’t really care about atomicity when it comes to these kinds of operations). Thankfully, we found a suitable client library, and we were able to use it without introducing lots of changes to our code base. It’s important to mention that, in our case, it was relatively simple since our applications didn’t care about atomicity when it came to our multi-key operations, but in case the need arises in the future, we can always use hash tags, which can be used to force certain keys to be stored in the same hash slot. This should be used carefully, however, as it can easily skew the data distribution across hash slots and across nodes.
Moving Forward
As mentioned, we took this in steps. So we started by just deploying, taking out the old Redis library and replacing it with the one in the market service, which is much better supported, and making sure it worked well before switching to cluster mode.
Then, since we use AWS Elasticache for a managed Redis deployment, we created an ElastiCache cluster of 3 nodes with cluster mode enabled (using Terraform, which we use to define and deploy all our infrastructure) only for the market service. But when we started applying this in code on the market service we faced an issue along the way…
More Obstacles
Turns out Redis Cluster is not supported in the Datadog APM library that we use, and since monitoring and observability are two key components to anything that we do at Thndr, we couldn’t move forward. We faced a dead end and were contemplating what to do. Should we wait until it’s supported? Should we fork the library and build support for it ourselves? The truth is, we were really tight on time, and we were expecting a substantial jump in our app load any day, so we had to find a solution that worked now.
Monkey patching to the rescue! Even though monkey patching is not really the most efficient or aesthetically pleasing code to write and maintain, it was a fast and effective option. We were able to monkey-patch the library and make sure monitoring was working on our staging environment in around 30 minutes.
Showtime and Results
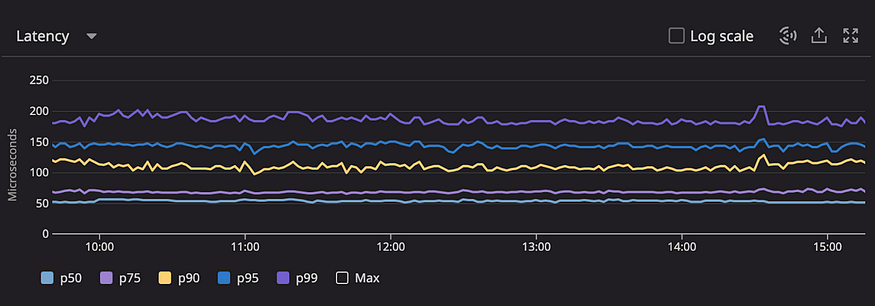
And finally, we were ready to deploy Redis cluster mode in one of our services and see it in action on production. Immediately upon deploying our solution to production, the results were immediate. The following graph was taken during market hours, and it shows Redis latency mapped just to mere microseconds!
Wrapping up
To sum it up, we discussed the problem, discovery, solution, and implementation of one of Thndr’s app’s technical debt items that had become a higher priority due to the app’s phenomenal growth in daily transactions and user base. At Thndr, we are firm believers in continuous improvement and doing things the right way. We also acknowledge that there will always be trade-offs and that technical debt should be prioritized during each iteration and at every level. However, we also know that there are many amazing projects and codebases for products that were not fortunate enough to continue. Every day, trade-offs are inevitable!


